
Knowledge Distillation Research Review

The latest advances and insights for Neural Network model compression with Knowledge Distillation

Knowledge Distillation is a process where a smaller/less complex model is trained to imitate the behavior of a larger/more complex model.
Particularly when deploying NN models on mobiles or edge devices, Pruning, and model compression in general, is desirable and often the only plausible way to deploy as the memory and computational budget of these devices is very limited.
Why not use potential infinite virtual memory and computational power from cloud machines? While a lot of NN models are running on the cloud even now, latency is not low enough for mobile/edge devices, which hinders utility and requires data to be transferred to the cloud which rises a lot of privacy concerns.
Preliminaries of Neural Network Knowledge Distillation
Response (Output logits) Distillation vs. Feature Distillation vs. Relation Distillation: This distinction is based on the knowledge that is transferred from a teacher network to a student network. If a student network is trained to reproduce the output logits distribution it is called Response Distillation. Instead, if a student network is trained to reproduce the intermediate representations, then it is called Feature Distillation. If a student network is trained to reproduce the relative response on a pair of inputs it is called Relation Distillation.
Offline Distillation vs. Online Distillation: If the teacher model is already trained and a student model is trained after transferring the knowledge from the teacher, then it is called Offline Distillation. If both the teacher and student models are trained in parallel, then it is called Online Distillation. (Online Distillation could be between models of the same size and same complexity where there are no teachers or students).
Distilling from ensembles of models: In this paradigm, a single model is obtained distilling the knowledge from an ensemble of models to lower the inference costs.
Self-distillation: Sometimes a model is trained to mimic the feature outputs of the Nth-layer at (N/3)th-layer or at (N/2)th-layer. Now, only N/2 or N/3 layers of the model are sufficient to produce the results of a full N-layer network. This can be seen as distilling a smaller model from a bigger model which is itself.
Contrastive Representation Distillation (ICLR 2020)
Outstanding problem: Instead of training a student model to imitate just the class independent output probabilities of a teacher model, training to imitate the representations of the teacher model transfers more knowledge from the teacher model to a student model.
Even though previous methods dealt with transferring representations of the teacher model, their loss functions are not designed to model the correlations and higher-order dependencies in the representational space using just a dot product between representations. This constrains the feature vectors of the student and the teacher to be of the same size, which doesn’t allow the possibility of having smaller student networks without any constraints on their architecture, which is most desired.
This work employs a contrastive learning approach based on mutual information to learn correlations in the representational space. The similarity between representations is estimated with a critic model that is trained along with the student model which takes two representations and outputs a similarity between 0 to 1, making it possible to have different sizes of feature vectors in teacher and student networks.
Proposed solution: Instead of just maximizing the dot product between the representations of a teacher model and a student model or minimizing L1 between them, this work proposes that we use mutual information as the criterion to maximize.
Mutual information is a measure between two variables that tells how much information is present in one variable about the other.
Adopting a contrastive learning framework, the authors train positive pairs which are student and teacher representations for the same input by increasing the mutual information between those representations. They also trained negative pairs which are student and teacher representations for different inputs by decreasing the mutual information between those representations.
Results and Conclusions: It is shown that the output probabilities of the student network trained with the proposed methods achieve higher correlations with the output probabilities of the teacher network.
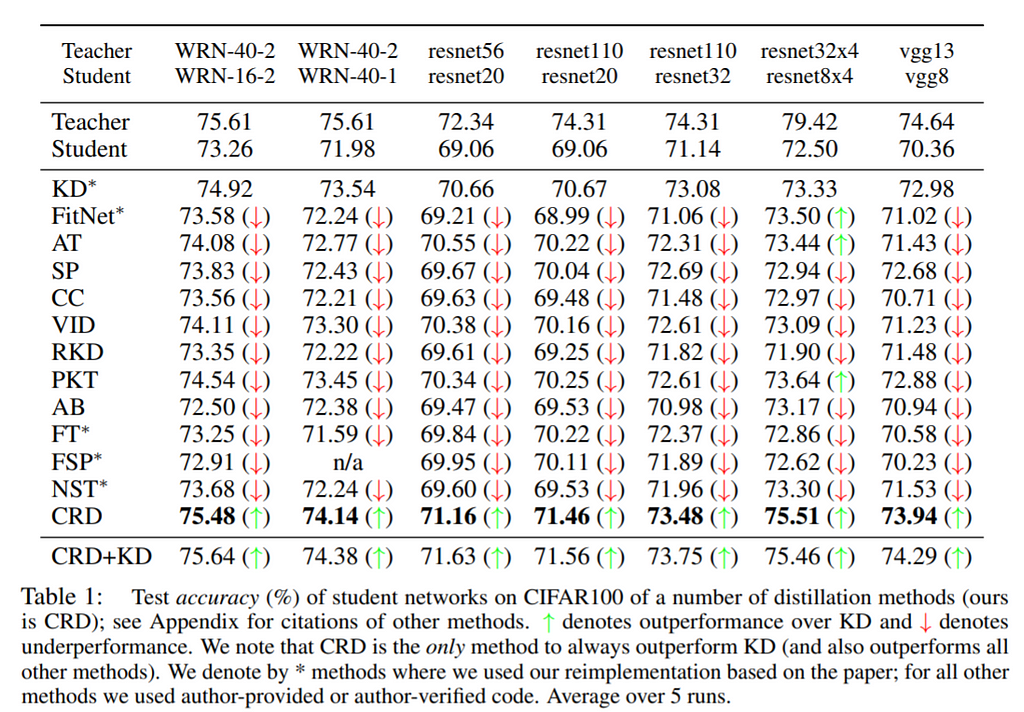
The proposed method outperforms many of the recently proposed Knowledge Distillations methods.
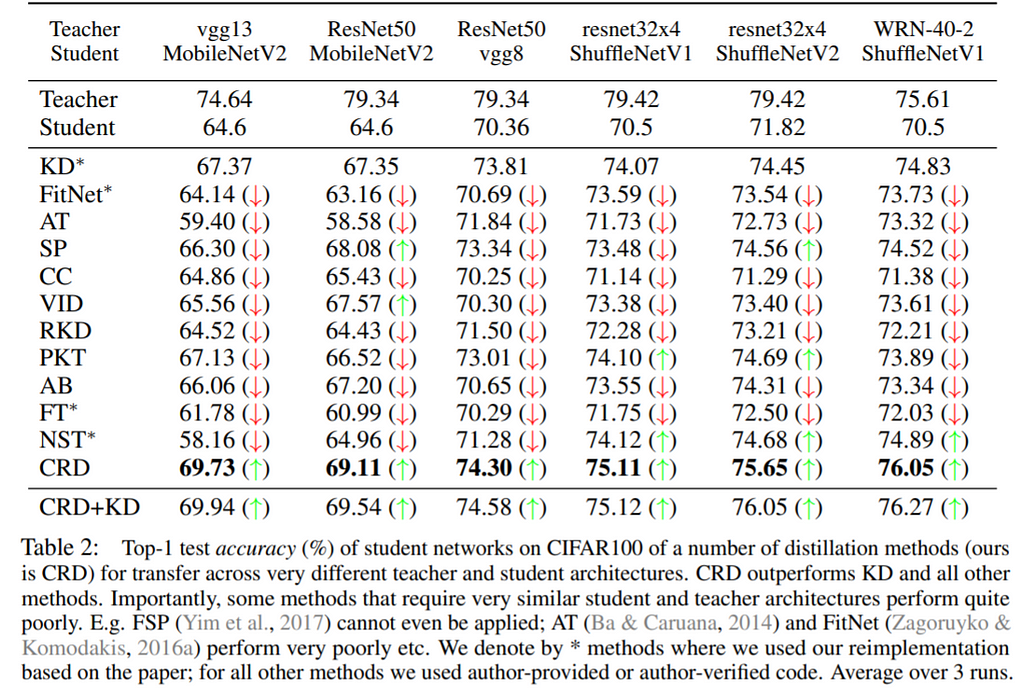
Also, the proposed method outperforms all other methods in cases where the architectures of the teacher and student models are very different.
Feature-map-level Online Adversarial Knowledge Distillation (ICML 2020)
Outstanding problem: Even though it is established that transferring knowledge from feature maps is more efficient than just transferring the knowledge of output logit distributions, no method exists to transfer the feature-map-level in an online knowledge distillation setting (where multiple models are trained simultaneously to predict the ground truth label and also to mimic each other’s behavior).
It is particularly hard to transfer the feature-map-level knowledge because the feature maps change more rapidly than the output logits and pose a major problem to distillation methods having to transfer representations from this moving target.
The current method overcomes this challenge with adversarial training by trying to make the representational distributions similar rather than individual representations.
Proposed solution: Given two networks, this work proposes three types of losses in the entire objective. 1. Cross-entropy between predicted and ground truth labels for each network. 2. KL divergence losses between the output logits of the two networks (both ways). 3. Discriminator loss where the representations of a particular network are treated as fake and representations from the other network are treated as real.
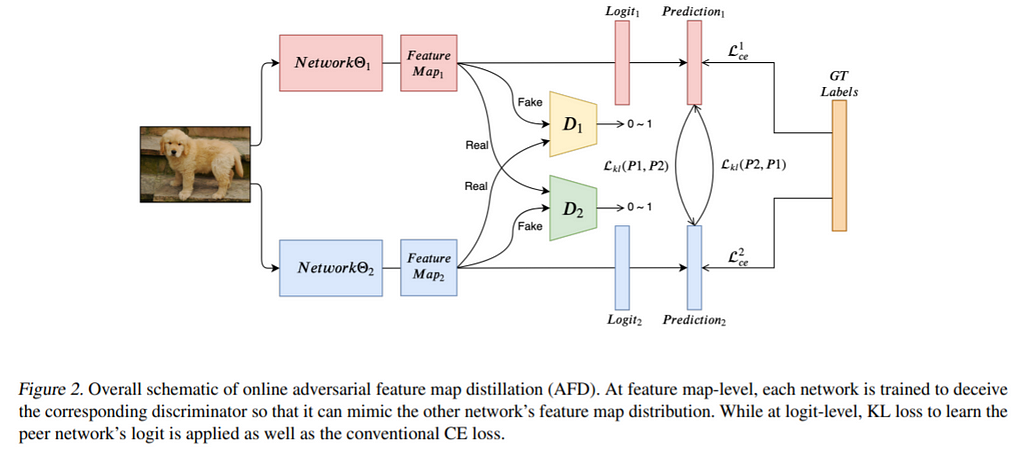
Cross-entropy loss brings in the information from the dataset. KL divergence acts as the standard knowledge distillation of output logits. And, finally, the discriminator losses would help the network to learn from other networks even though the actual representations are changing by pushing for the entire distributions to be similar.
Results and Conclusions: The proposed method outperforms the direct alignment-based methods (L1).
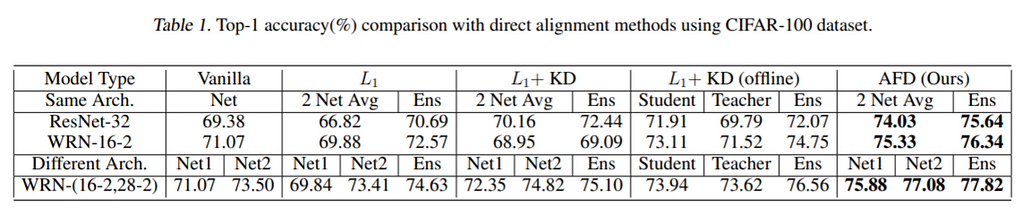
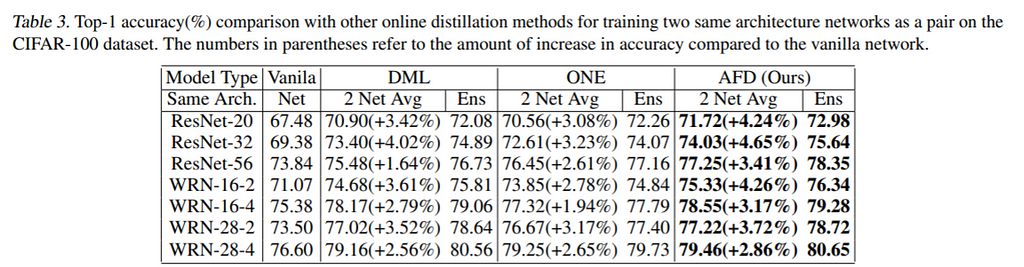
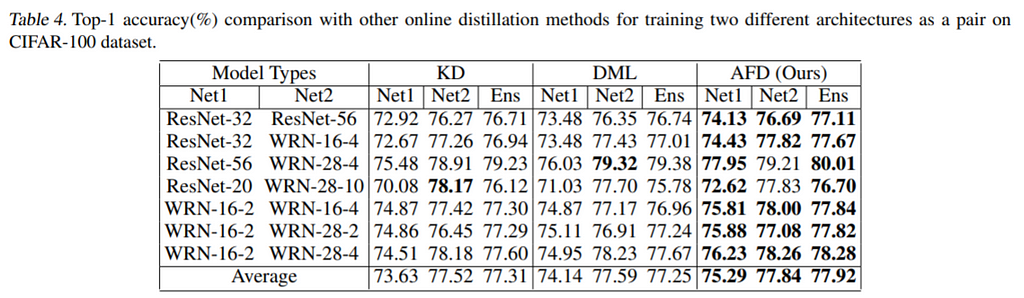
The proposed method also outperforms the previous online distillation methods in both cases with the same networks and different networks.
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers (NeurIPS 2020)
Outstanding problem: Existing methods dealt with distilling the task-specific models where the pre-trained transformer-based language models are fine-tuned, but no work exists which deals with task-agnostic distillations of pre-trained models which are then fine-tuned with fewer resources compared to the large pre-trained models.
The existing distillation methods for transformers either constrain the number of layers, or the hidden representation size of the student model, or adopts layer-to-layer distillation which needs extra parameters.
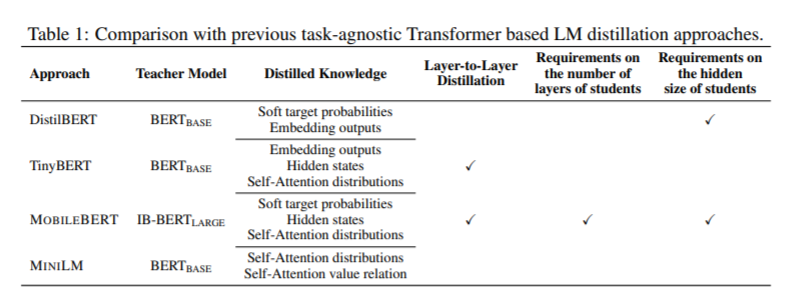
Proposed solution: This proposes a distillation method that mimics the behavior of the last layer of a transformer which removes the constraint on the number of layers of a student network.
The novelty of this work is that it also distills the so-called value-relational knowledge which mimics the value-value scaled dot product of a teacher model along with attention weights distribution of the self-attention layer as previous methods do. See the figure below.
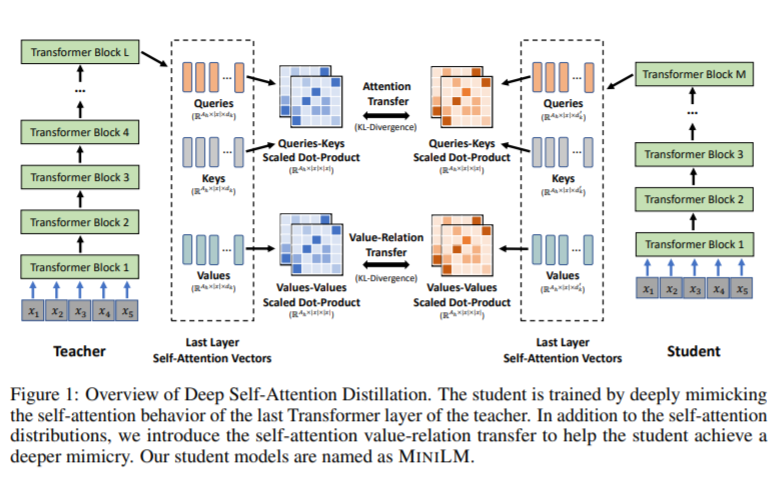
As the value-relational knowledge is a pair-wise relational knowledge, it removes the constraint on the hidden representation size of a student model.
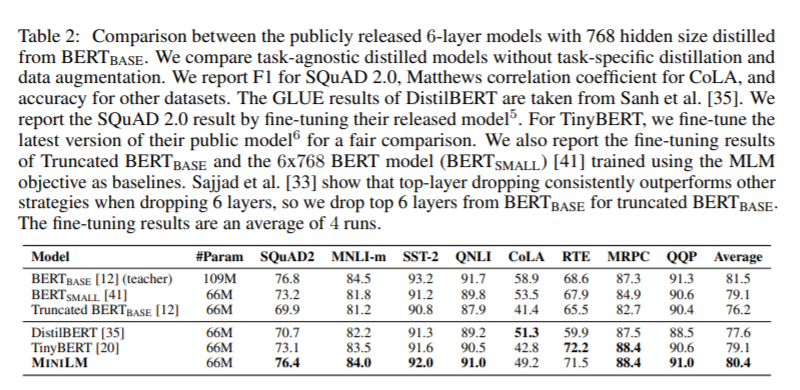
Results and Conclusions: The student model trained with this model, when fine-tuned, outperforms the task-specific distilled methods for a range of downstream tasks where all of the models are six-layer transformer models with a hidden representation size of 768.
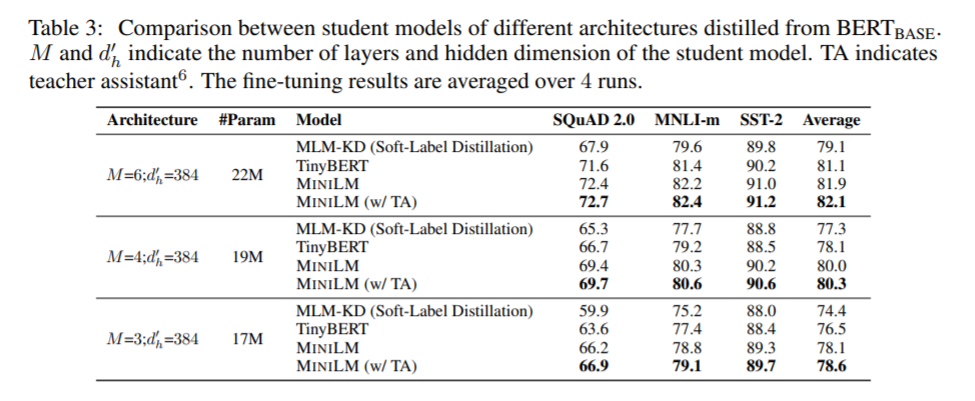
The proposed method also outperforms different methods for 3-, 4-, and 6-layer transformers for small hidden representation sizes as well.
Residual Distillation: Towards Portable Deep Neural Networks without Shortcuts (NeurIPS 2020)
Outstanding problem: Residual connections (a layer takes the output of the last layer as well as the input of the last layer, i.e. F(x)+x) avoid vanishing gradient problem and allow us to train very deep neural networks (ResNet-152!). But these residual connections occupy 40% of the total memory usage because of the need to store more activations and gradients.
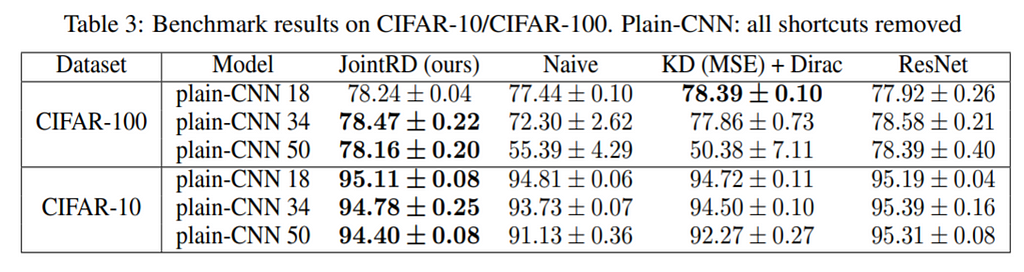
Plain-CNN would have low latency and a low memory footprint due to the removal of residual connections with a 20–30% reduction. See figure below.
A distillation method that learns a network without these residual connections, but with the same accuracy, is very desirable.
Proposed solution: This work proposes to distill the knowledge from a teacher ResNet with residual connections into a plain-CNN student with all the residual connections removed.
To avoid a vanishing gradient problem, this method trains the plain-CNN jointly with the corresponding ResNet. Specifically, during the forward pass, the output of the initial layers are passed both into the deeper layers of plain-CNN along with the deeper layers of the ResNet.
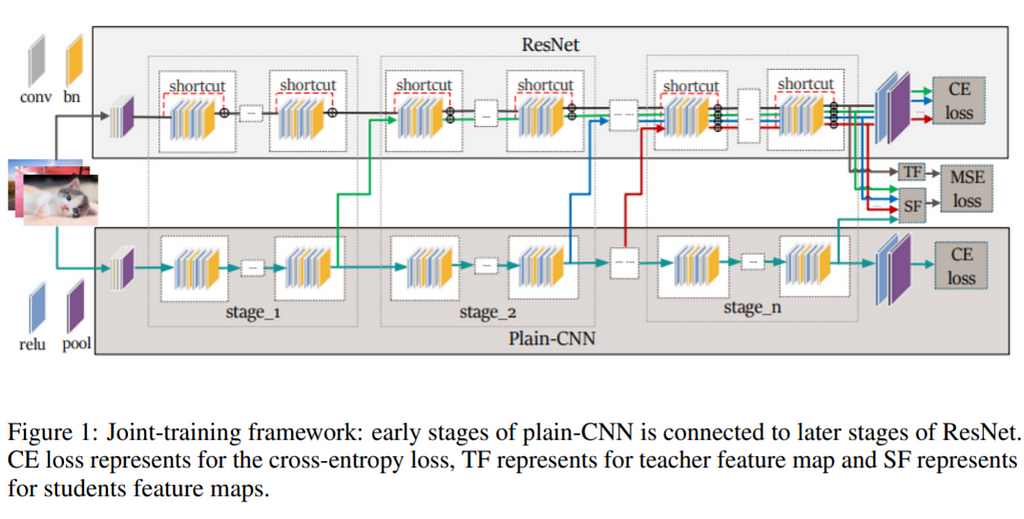
Thus, the gradients flow through the initial layer of the plain-CNN because of the residual connections of the ResNet. But the inference after training is only done with the plain-CNN, thus avoiding memory and computations bandwidth of having residual networks.
Results and Conclusions: The plain-CNN trained with this method shows a performance competitive with the corresponding ResNet and outperforms others knowledge distillation methods.
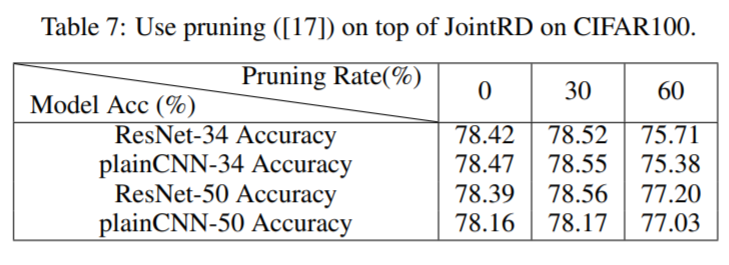
Even with pruning on top of knowledge distillation, plain-CNN performs competitively and some times better than the corresponding ResNet with pruning ratios of 30 and 60 percent.
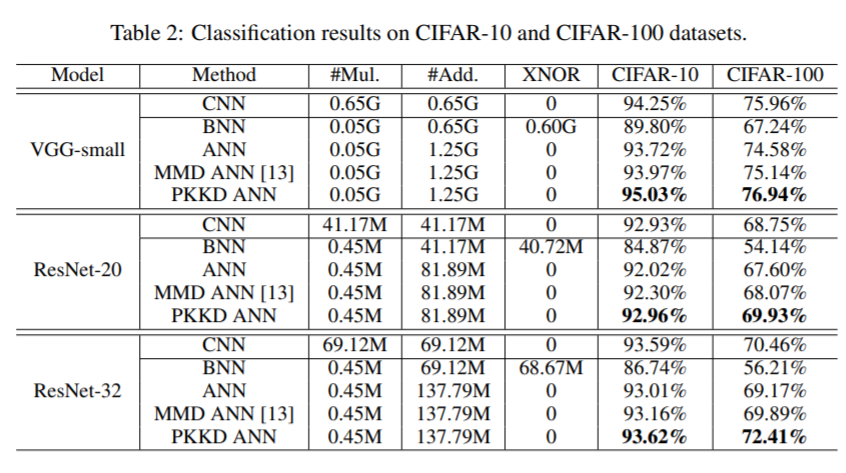
Kernel-Based Progressive Distillation for Adder Neural Networks (NeurIPS 2020)
Outstanding problem: Adder Neural Networks (ANNs) replace the convolutional operation in CNNs with additions (L1 operator) thus reducing the computational resources amenable to deploying in low-resource environments such as mobile phones and cameras.
In practice it is observed that ANNs are difficult to optimize and thus the performance of ANNs is still lower than CNNs. This calls for methods that can train ANNs efficiently and increase their performance to be competitive with traditional CNNs.
Proposed solution: This work proposes a method to distill the knowledge from CNN into an ANN, both the knowledge of output logit distributions and intermediate representations.
First, the authors observe that the optimal weight initialization of ANNs is based on Laplace distribution, but Gaussian distribution is used for CNNs and that the representation distributions in ANNs and CNNs are of different characteristics.
Thus, they devise a kernel method to transform the intermediate features from ANNs and CNNs into one vector space to enable distillation. They call this method a progressive kernel-based knowledge distillation (PKKD).

Results and Conclusions: PKKD ANN outperforms Binary Neural Networks (BNNs) and other variants of ANNs on CIFAR-10, CIFAR-100.
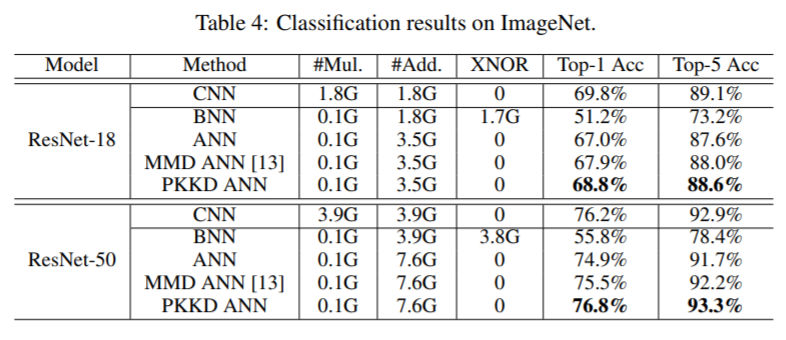
And also on the ImageNet dataset.
Conclusion
Research on Neural Network Distillation, and, more generally, NN compression, is evolving to be more scientific and rigorous. One of the reasons is, undoubtedly, the interaction between the wide adoption of deep learning methods in computer vision & NLP and elsewhere and the increasing amount of memory, energy, and computational resources required for state-of-the-art methods.
Due to the research in 2020, we learned that imitating the feature representations are more efficient than imitating logits alone. We can now make a ResNet into a feed-forward network without much degradation in performance and we know a more efficient way to self-distill large language models.
Going into 2021, it would be great to see approaches that combine distillation with pruning and quantization to be more efficient than simply performing two or three of them in sequence.
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deep learning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Editorially independent, Heartbeat is sponsored and published by Comet, an MLOps platform that enables data scientists & ML teams to track, compare, explain, & optimize their experiments. We pay our contributors, and we don’t sell ads.
If you’d like to contribute, head on over to our call for contributors. You can also sign up to receive our weekly newsletters (Deep Learning Weekly and the Comet Newsletter), join us on Slack, and follow Comet on Twitter and LinkedIn for resources, events, and much more that will help you build better ML models, faster.
Knowledge Distillation Research Review was originally published in Heartbeat on Medium, where people are continuing the conversation by highlighting and responding to this story.